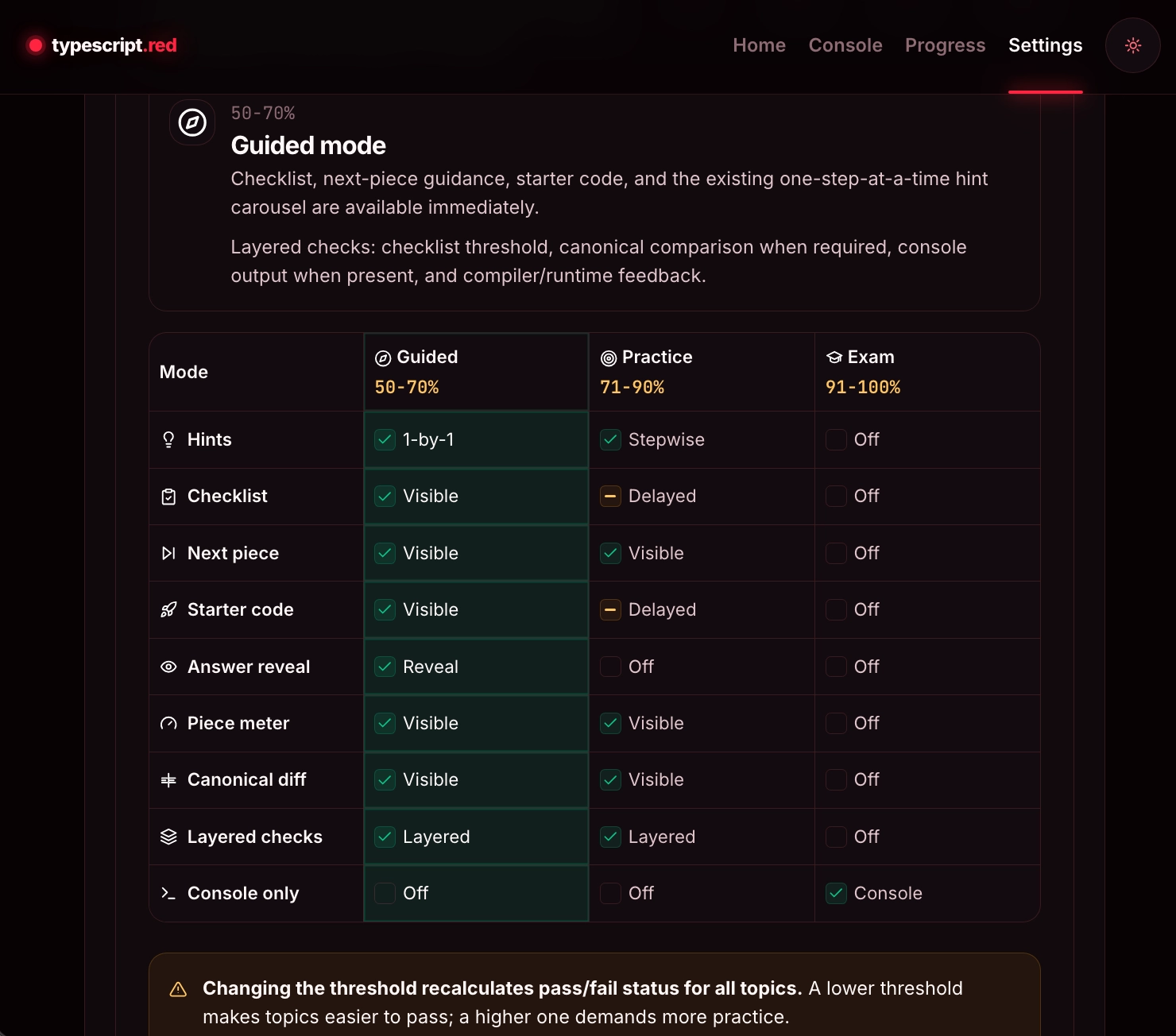
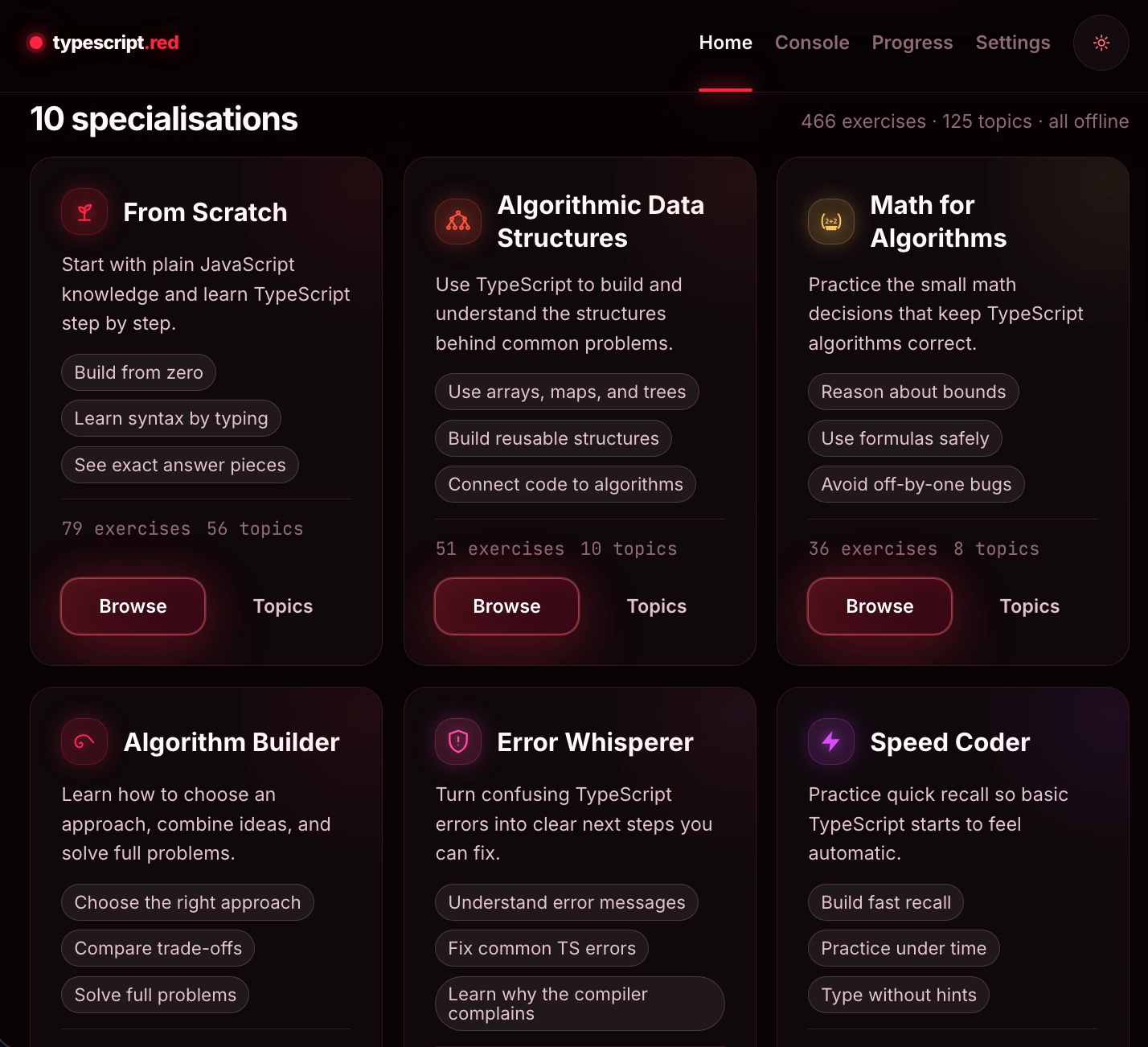
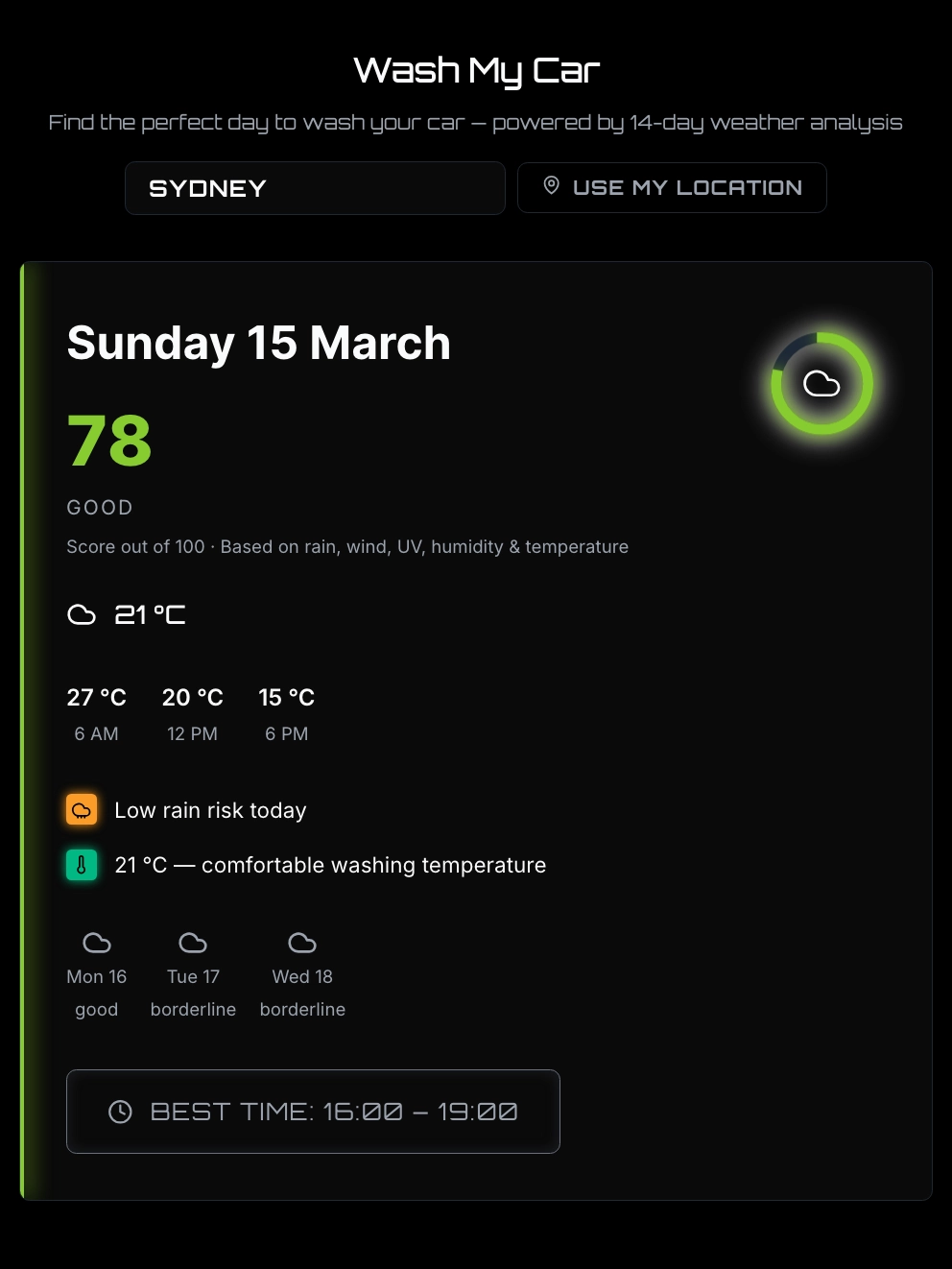
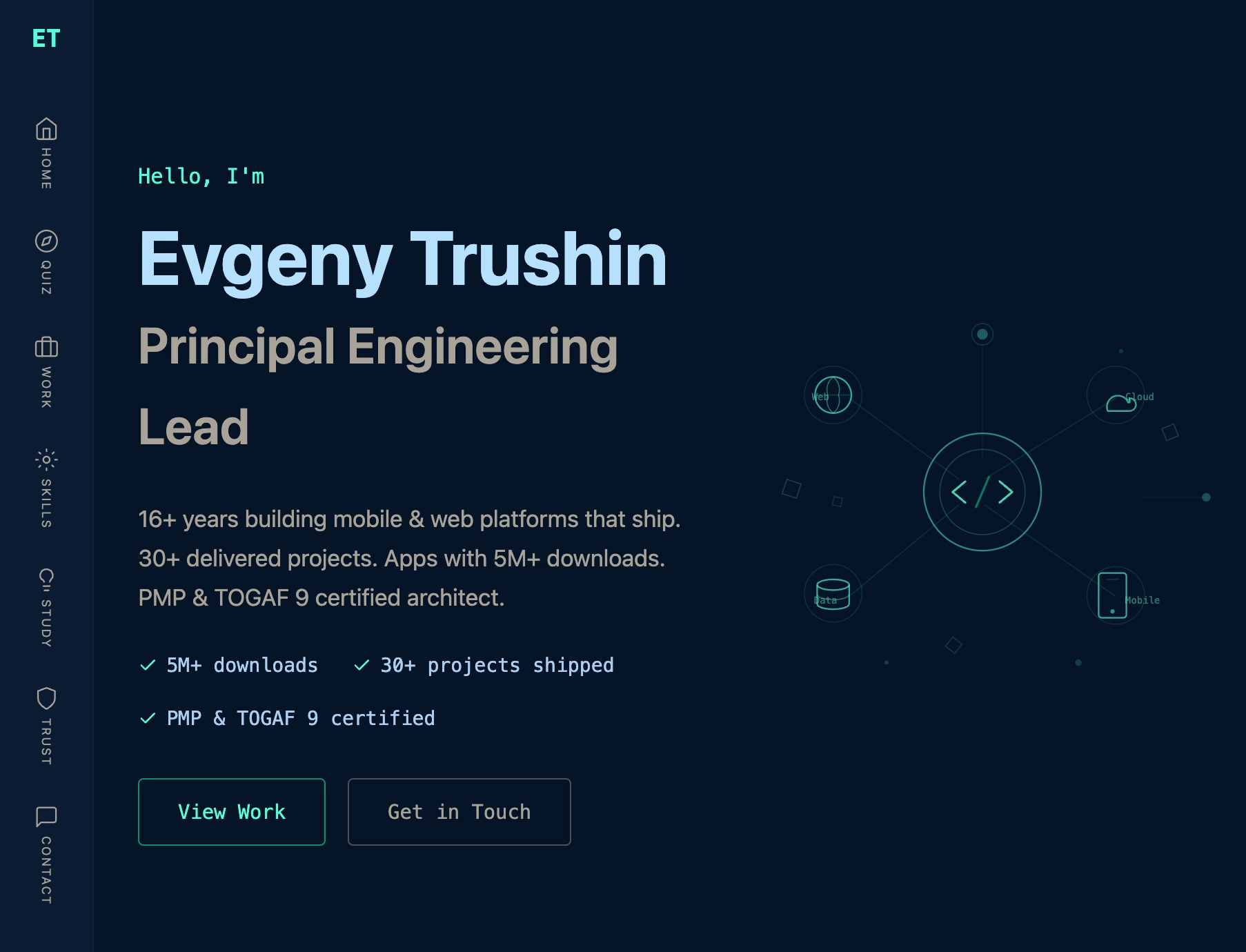
Message capsr/ClaudeAI
Message caps turn long coding sessions into a productivity tax.
“Restarting chats to avoid hitting the cap feels like a weird productivity tax” and transferring context to the next session loses small details.
Selfdev angle: the handoff is not a messy summary. The next todo/ increment, how/ rules and organism_state.json are stored in the repo.